PE 포맷이란 Portable Executable 약자로 윈도우 운영체제에서 사용되는 실행 가능한 파일 형태를 말한다.
아래서 설명할 PE 파일은 말그대로 PE 포맷 구조를 가지는 파일이다.
대표적인 포맷인 만큼 다양한 분석툴에서 PE파일을 분석할 수 있다.
PE Viewer가 대표적이며 본 포스팅에선 개념 이해를 위해 HxD를 이용해 설명하도록 하겠다.
2. PE 파일 종류
PE 포맷을 가진다고 무조건 실행하는 계열의 확장자만 해당되는 것이 아니다.
다음과 같은 다양한 파일 포맷이 PE 구조를 가진다. 대표적으로 .exe와 .dll이 존재한다.
실행 계열 : EXE, SCR
드라이버 계열 : SYS, VXD
라이브러리 계열 : DLL, OCX, CPL, DRV
오브젝트 파일 계열 : OBJ
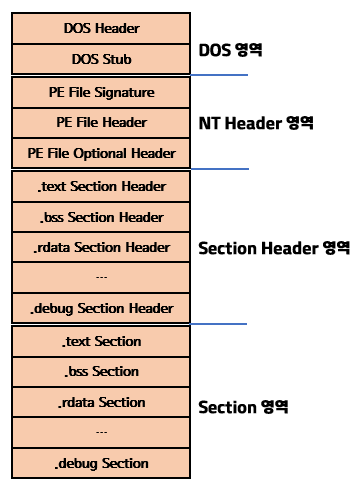
3. PE 파일 구조
PE 파일은 다음과 같이 구성되어있다.
Header + Section
Header란 실행 파일의 성격과 특징을 나타내며(프로그램 구동 정보 등등),
Section은 구체적이고 세부적인 기능을 나타낸다(코드, 전역변수 등등) .
위 구조를 그림으로 좀더 자세히 표현하자면 아래와 같다.
각 영역에 대해 살펴보자.
4. PE 파일 구조 - DOS 영역
MS에서 DOS 파일에 대한 하위 호환성을 고려하여 PE 파일 포맷을 만들었다.
DOS 영역의 두가지 영역을 살펴보자.
1) DOS Header
이제부터 몇몇 영역을 아래와 같이 소스코드로 나타낼 건데, 이는 MS에서 제공하는 winnt.h에서 가져온 내용이다.
typedef struct _IMAGE_DOS_HEADER {
WORD e_magic; // Magic number > DOS Signature : 4D5A("MZ")
WORD e_cblp;
WORD e_cp;
WORD e_crlc;
WORD e_cparhdr;
WORD e_minalloc;
WORD e_maxalloc;
WORD e_ss;
WORD e_sp;
WORD e_csum;
WORD e_ip;
WORD e_cs;
WORD e_lfarlc;
WORD e_ovno;
WORD e_res[4];
WORD e_oemid;
WORD e_oeminfo;
WORD e_res2[10];
LONG e_lfanew; // Offset of NT Header
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
DOS Header 영역으로 중요한 정보는 두가지다.
첫번째 e_magic 값과 e_lfanew 값이다.
e_magic : DOS Signature 값으로 0x4D5A("MZ")라는 값을 가진다.
e_lfanew : NT Header의 오프셋 주소를 가진다. DOS Stub 영역을 점프하는 역할을 한다.
2) DOS Stub
에러메세지를 출력하는 부분이다.
가변적인 영역으로 옵션에 의해 존재여부를 결정한다.
없어도 파일은 잘 실행된다.
5.PE 파일 구조 - NT Header 영역
NT Header 영역은 3가지 영역이 존재한다.
1) PE File Signature
NT Header 시작부분에 위치하며 PE File Signature 값으로 0x5045("PE")라는 값을 가진다.
2) PE File Header(IMAGE_FILE_HEADER)
typedef struct _IMAGE_FILE_HEADER {
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
이 부분에서 중요한 정보는 Machine, NumberOfSections, SizeOfOptionalHeader, Characteristics로 4가지 이다.
Machine : CPU별로 고유한 값을 가진다. 0x014C는 IA-32, 0x0200은 IA-64와 같은 값을 가지고 있다.
NumberOfSections : 섹션의 갯수를 나타내며, 1개 이상의 값을 가진다. *만약 정의된 섹션수 > 실제 섹션 : error *만약 정의된 섹션수 < 실제 섹션 : 정의된 섹션수만큼 인식
SizeOfOptionalHeader : 마지막 멤버 Optional Header32 구조체의 크기를 나타낸다.
Characteristics : 파일의 속성을 나타낸다. 실행 가능한 파일인지, dll 파일인지와 같은 정보 등을 나타낸다.
3) PE File Optional Header(IMAGE_OPTIONAL_HEADER)
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
#define IMAGE_NUMBEROF_DIRECTORY_ENTRIES 16
typedef struct _IMAGE_OPTIONAL_HEADER {
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
DWORD BaseOfData;
DWORD ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;