반응형

지난 시간에 STL에 대해 알아보았다.
이번시간은 STL 시퀸스 컨테이너 중 많이 활용되는 vector에 대해 공부해보려한다.
긴말필요없이 시작해보자. :)
1. vector란?
vector란 시퀸스 컨테이너 중 하나로 '메모리가 동적으로 할당되는 배열'이다.
이를 이용하여 C++에서 동적 배열을 쉽게 구현할 수 있다.
vector는 원소를 저장할 때 메모리에 연속적으로 저장되며, 이로인한 장점과 단점이 존재한다.
순차적이라 임의 접근시 속도는 빠른편이나, 원소를 삽입하거나 제거할때 모든 원소를 옮기는 과정을 거치다보니 속도가 느릴수있다.
vector를 사용하기 위해선 <vector> 헤더파일을 include 해주어야하며,
std::vector<[데이터타입]> [변수이름] 형식으로 선언해 사용할 수 있다.
(using namespace std;로 std 생략하여 편하게 작성가능)
2. vector - 생성자
vector 생성자는 다음과 같이 사용 가능하다.
- vector<int> vec
- 빈 vector 컨테이너 vec을 생성
- vector<int> vec(3);
- 3개의 원소를 갖는 vec을 생성(기본값 초기화)
- vector<int> vec(3, 4);
- 4로 초기화된 3개의 원소를 갖는 vec을 생성
- vector<int> vec2(vec);
- vec 컨테이너를 복사한 vec2를 생성
- vec 컨테이너를 복사한 vec2를 생성
3. vector - 멤버 함수, 멤버 형식
다음은 vector 멤버 함수와 멤버 형식이다.
대표적인 몇몇개를 정리해보았으며 데이터타입이 int라고 가정하고 작성하겠다.
- 멤버 함수
- vec.assign(2, 3);
- vec에서 3이란 값으로 2개의 원소를 할당
- vec에서 3이란 값으로 2개의 원소를 할당
- vec.at(3);
- vec의 3번 인덱스를 참조(범위 점검 > 안전함)
- vec[3];
- vec의 3번 인덱스를 참조(범위 점검 X > 속도빠름)
- vec.front();
- vec의 첫번째 원소를 참조
- vec.back();
- vec의 마지막 원소를 참조
- vec.clear();
- vec의 모든 원소를 제거하며 메모리는 그대로 내비둠
- vec.push_back(5);
- vec에 5란 원소를 push(추가)
- vec.pop_push();
- vec에 마지막 원소를 pop(제거)
- vec.insert(3, 4); vec.insert(3, 4, 2);
- vec의 3번 인덱스에 4란 값 삽입
- vec의 3번 인덱스부터 4개의 2란 값 삽입(밀림)
- vec.erase(iterator)
- iterator가 가리키고 있는 원소를 제거
- size는 줄지만 할당된 메모리는 그대로
- vec.clear();
- vec의 모든 원소를 제거
- size는 0이되며 할당된 메모리는 그대로
- vec.begin();
- vec의 첫번째 원소를 가리킴
- iterator와 같이 사용
- vec.end();
- vec의 마지막 다음 주소를 가리킴
- iterator와 같이 사용
- vec.size();
- vec의 원소 갯수 참조
- vec.capacity();
- vec이 할당된 공간 크기 리턴
- 기존 메모리의 2배씩 증가하게 되며, 미리 정해둔 만큼 한번에 동적할당을 해두어 효율을 높이는 것이 목적
- 원소갯수 = 1 -> capacity = 1, 2 -> 2, 3 -> 4, 4 -> 4, 5 -> 8...
- vec.empty();
- vec의 size가 0이면 참, 0보다 크면 거짓
- vec.swap(vec2);
- vec1와 vec2의 원소와 할당된 메모리를 맞바꿈
- vector<int>().swap(vec); 형태로 할당된 메모리가 0인 임시 객체를 만들어 vec capacity 없앨때 사용 가능
- 멤버 형식
- allocator_type
- 메모리 관리자
- iterator
- 반복자
- pointer
- value_type *
- refernce
- value_type &
- reverse_iterator
- 역 반복자
- size_type
- 인덱스, 원소 갯수 등
- value_type
- 원소 형식
- 원소 형식
4. vector - 연산자
마지막은 vector의 연산자이다.
- ==, !=
- == : 두 vector 컨테이너의 모든 원소가 같으면 참, 아니면 거짓
- != : 두 vector 컨테이너에서 하나라도 원소가 다르면 참, 아니면 거짓
- <, >, <=, >=
- vector 컨테이너간 크기 비교
- vector 컨테이너간 크기 비교
5. vector 구조 및 실습
위에서 설명한 vector의 구조는 다음 그림과 같다.

실습은 지난 vector 실습 소스를 수정하여 진행할 예정이다.
#include <iostream>
#include <vector>
using namespace std;
int main(void) {
vector<int> vec; //빈 컨테이너 vec 생성
vector<int>::iterator vecit;
vec.assign(1, 10); //비어있는 vec에 10이란 값을 1개 원소 부여
cout << "vec.at(0) : " << vec.at(0) << endl; //vec의 0번 인덱스 참조(범위점검O)
cout << "vec[0] : " << vec[0] << endl; //vec의 0번 인덱스 참조(범위점검X)
vec.push_back(20); //vec에 20 push
vec.push_back(30); //vec에 30 push
vec.push_back(40); //vec에 40 push
cout << "vec의 첫번째 원소 " << vec.front() << endl;
cout << "vec의 마지막 원소 " << vec.back() << endl;
cout << "vec의 사이즈 " << vec.size() << endl;
cout << "vec의 할당된 메모리 " << vec.capacity() << endl;
for (vecit = vec.begin(); vecit != vec.end(); vecit++) { //연산자로 vec의 begin부터 end까지 출력
cout << *vecit << endl; //참조하는 값 출력
}
vector<int> vec2(vec); //vec를 복사한 vec2 생성
cout << "vec2.at(0) : " << vec2.at(0) << endl; //vec2의 0번 인덱스 참조(범위점검O)
cout << "vec2[0] : " << vec2[0] << endl; //vec2의 0번 인덱스 참조(범위점검X)
for (vecit = vec2.begin(); vecit != vec2.end(); vecit++) { //연산자로 vec2의 begin부터 end까지 출력
cout << *vecit << endl; //참조하는 값 출력
}
cout << "vec2이 비어있는가? "<< vec2.empty() << endl; //vec2는 안비어있으므로 0
cout << "vec2.clear 수행" << endl;
vec2.clear(); //모든 원소 지움
cout << "vec2이 비어있는가? " << vec2.empty() << endl; //vec2 원소는 모두 비어있으므로 1
cout << "vec2의 사이즈 " << vec2.size() << endl; //모두 비어있기때문에 0
cout << "vec2의 할당된 메모리 " << vec2.capacity() << endl; //clear해도 할당된 크기는 그대로
cout << "vector<int>().swap(vec2) 수행" << endl;
vector<int>().swap(vec2); //임시객체를 만들어 swap하며 vec2의 메모리 초기화
cout << "vec2의 할당된 메모리 " << vec2.capacity() << endl; //clear해도 할당된 크기는 그대로
return 0;
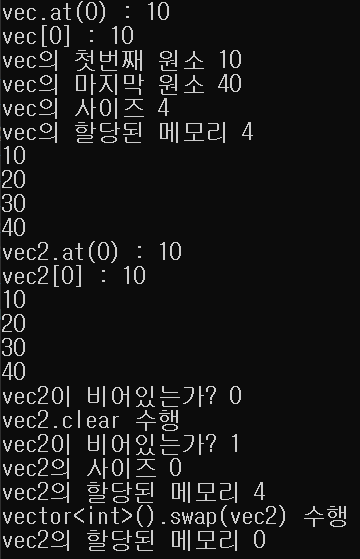
}실행결과는 다음과 같다.
여기까지 vector 공부를 마친다. 이와같이 당분간 시퀸스 컨테이너 포스팅을 진행할 예정이다.
반응형
'Programming > Language' 카테고리의 다른 글
| [C++] STL - stack 공부 (0) | 2020.05.11 |
|---|---|
| [C++] STL - list 공부 (0) | 2020.05.07 |
| [C++] STL(Standard Template Library) 시작 (0) | 2020.05.05 |
| [C++] 템플릿(Template) 공부 (0) | 2020.05.04 |
| [C++ 프로그래밍 책 정독 4일차] 9장-10장 개인 정리 및 이해 (0) | 2020.02.26 |