C++ 코드를 작성하다보면 클래스나 함수를 사용할때 다양한 자료형을 처리해야하는 경우가 생긴다.
이럴 경우 템플릿(Template)을 이용하면 쉽게 작성이 가능하다.
이번 시간엔 템플릿에 대해 알아보겠다.
1. 템플릿(Template)?
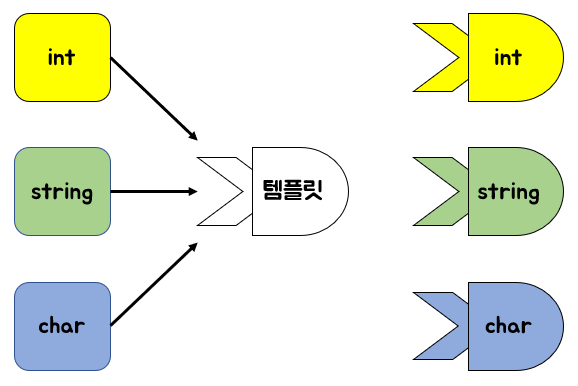
템플릿이란 여러 자료 형으로 클래스나 함수를 사용할 수 있도록 만들어 놓은 '틀'이다.
아래 그림과 같이 어떠한 자료형이 들어왔을때 템플릿을 이용하면 재선언없이
클래스나 함수를 해당 자료형으로 사용할 수 있게된다.
템플릿은 함수 템플릿과 클래스 템플릿으로 나누어지며 차근차근 설명해보록 하겠다.
2. 함수 템플릿
함수 템플릿은 말그대로 여러 함수를 만들어낼 수있는 틀과 같다.
일반적으로 다른 자료형을 함수에 적용시키고자 할때 함수 오버로딩을 사용하여 해결한다.
그러나 사용자가 직접 정의한 타입을 해당 함수에 적용시키기 위해선 함수 오버로딩 사용은 제한적이다.
이럴때 함수 템플릿을 사용한다.
자료형이 정해지지않은 두 수를 더하고 반환하는 함수를 만들어보자. 형태는 다음과 같다.
#include <iostream>
using namespace std;
template<typename T>
T Sum(T a, T b) {
T tmp;
tmp = a + b;
return tmp;
}
int main(void) {
int a = 3, b = 2;
double c = 3.3, d = 2.2;
int res1 = Sum(a, b);
double res2 = Sum(c, d);
cout << "res1 = " << res1 << ", res2 = " << res2 << endl;
return 0;
}
코드를 보면 int 형과 double 형의 자료형 데이터들을 하나의 함수에서 더하기를 처리하고 받아오는 것을 볼 수 있다.
우선 template<typename T> 형태로 템플릿 사용을 선언한다.
typename(class로 작성 가능)을 정하고 자료형 부분에 해당 타입이름인 T를 넣어준다.
여기서 T는 템플릿 매게변수이며 template<typename T1, typename T2> 형태와 같이 여러개 선언도 가능하다.
이제 들어오는 값의 자료형에 따라 알맞게 해당 함수에서 데이터를 처리하게 된다.
실행 결과는 다음과 같다.

3. 클래스 템플릿
클래스 템플릿은 여러 클래스를 만들어낼 수 있는 틀이다.
함수 템플릿과 차이점이 있는데 클래스 템플릿은 함수 템플릿과 달리 오버로드가 되지않는다.
또하나의 차이점은 함수 템플릿은 완전 특수화만 가능하고 부분 특수화는 오버로드를 통해서 구현하는 수밖에없고,
클래스 템플릿은 완전 특수화와 부분 특수화가 모두 가능하다는 특징이 있다.
*특수화 : 특정 타입에 대해서만 다르게 동작하도록 만드는 것
자료형이 정해지지않은 두 수를 더하고 출력하는 함수를 포함한 클래스를 만들어보자. 형태는 다음과 같다.
#include <iostream>
using namespace std;
template<typename T>
class Sum {
private:
T res;
public:
Sum(T a, T b) : res(a+b) {}
void printSum() {
cout << res << endl;
}
};
int main(void) {
int a = 3, b = 2;
double c = 3.3, d = 2.2;
Sum<int> isum(a, b);
Sum<double> dsum(c, d);
isum.printSum();
dsum.printSum();
return 0;
}
template<typename T>로 함수 템플릿과 같고 클래스를 선언한다.
이후 private으로 템플릿 매게변수로 res를 선언해주고 printSum()함수로 매게변수로 받아온 a와 b의 합을 출력한다.
참고로 Sum<int> isum(a, b)를 보면 알 수 있겠지만 클래스의 경우 함수 템플릿과 달리 자료형 정보를 담아줘야 한다.
실행 결과는 다음과 같다.

4. 장점과 단점
장점 : 타입별로 클래스나 함수를 일일히 만들 필요가 없어진다.
단점 : 실행파일 용량이 커질수도 있으며 컴파일 시간이 길어진다.
추가적으로 C++14부터 변수 템플릿이라는게 등장하는데 관심있는 독자분께선 추가로 찾아서 공부하시길 바란다.
여기까지 템플릿에 대한 공부를 마친다. 계속해서 사용해보며 익숙해지는 것이 우선인 것같다. 추후 포스팅은 해당 포스팅을 시작으로 STL에 대한 내용을 본격적으로 다뤄보려고 한다.
'Programming > Language' 카테고리의 다른 글
| [C++] STL - vector 공부 (0) | 2020.05.06 |
|---|---|
| [C++] STL(Standard Template Library) 시작 (0) | 2020.05.05 |
| [C++ 프로그래밍 책 정독 4일차] 9장-10장 개인 정리 및 이해 (0) | 2020.02.26 |
| [C++ 프로그래밍 책 정독 3일차] 7장-8장 개인 정리 및 이해 (0) | 2020.02.25 |
| [C++ 프로그래밍 책 정독 2일차] 4장-6장 개인 정리 및 이해 (0) | 2020.02.24 |